I Told AI to Write Tests First. It Wrote 3,400 of Them.
TDD with AI agents sounded like the right call. Then I got 3,400 tests, half of them testing JSON files and config. Here's what I learned fixing it.
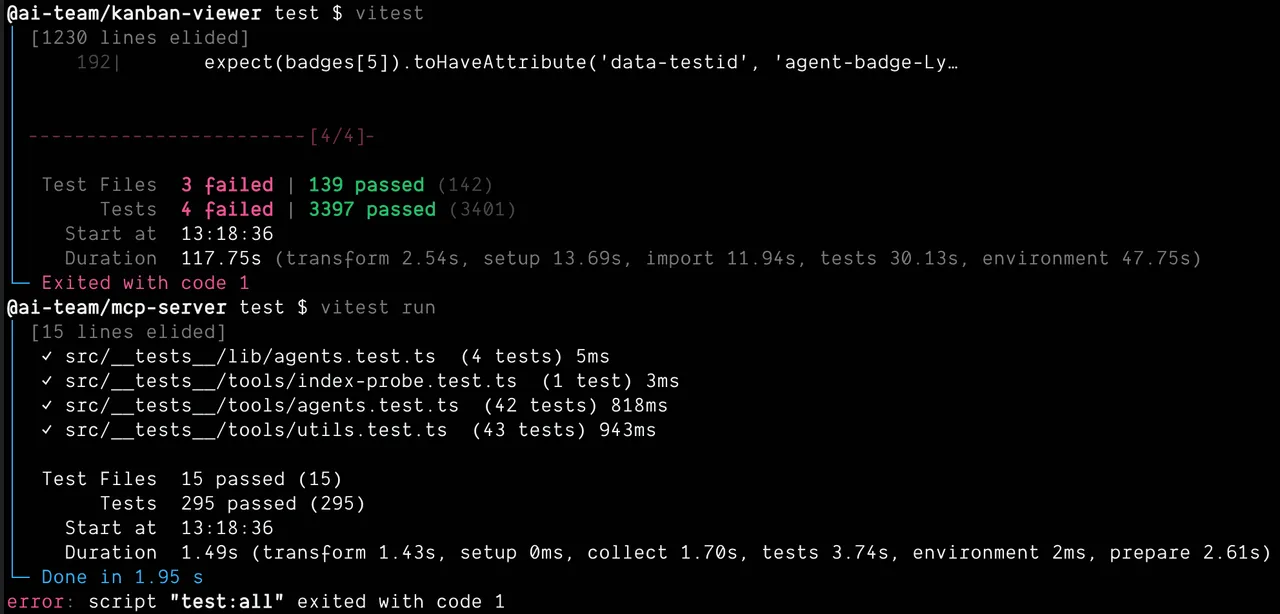
Three thousand, four hundred tests. That’s what I got when I told my AI agent pipeline to write tests before code.
I’ve been pushing dev teams to write tests first for years. They rarely do. Write the test, watch it fail, make it pass. Simple in theory. In practice, nobody wants to write the test at 4pm on a Friday when the feature is almost done and they just want to ship it.
So when the data started coming in on AI-generated code, TDD felt like the obvious guardrail. CodeRabbit found that AI code has 1.7x more issues than human code, with 75% more logic errors1. AI writes code that looks right, passes a code review, and breaks in production. Tests-first seemed like the fix.
So I built it. And the AI did exactly what I asked. It wrote tests for TypeScript features. Tests for API services. Tests for JSON config files. Tests for type definitions. Tests that checked whether an environment variable existed. Tests that verified a JSON file had the right keys.
Three thousand four hundred tests, and half of them were testing things that don’t run, don’t change, and don’t need a test suite.
The AI didn’t screw up. I screwed up. I said “write tests for everything” and it wrote tests for everything. That’s the thing about AI agents: they are extremely literal. That’s a feature and a bug.
This is the story of what I had to fix, and what the fixed version looks like.
Why TDD + AI Is the Right Call
Before I tear into what went wrong, the idea deserves credit. Because the idea is good.
The thing about TDD for AI is that it solves a different problem than TDD for humans. With humans, TDD is a discipline hack. With AI, it’s a correctness hack.
Think about those CodeRabbit numbers: 75% more logic errors, 64% more maintainability issues, 57% more security vulnerabilities1. That’s AI writing code with no target to hit. No failing test to satisfy. Just “implement this feature” and hope for the best. The code looks clean, passes a review, and breaks in ways you don’t catch until production.
Give the AI a test suite to pass and the dynamic changes completely. The test becomes the contract. The AI has a definition of done that isn’t vibes. Pass the tests, ship the code. Fail the tests, try again.
I couldn’t get human developers to write tests first. But AI doesn’t have ego. It doesn’t skip the test because it’s 4pm and the feature is almost done. You set the constraint, and it follows the constraint. Every time.
So tests-first was genuinely the right instinct. The problem was in the execution.
What Actually Went Wrong
I built a pipeline. Work items go in, agents process them, code comes out. One of those agents - Murdock, the QA agent - writes tests before the builder touches anything.
The instruction was straightforward: write tests for this work item before implementation begins.
The work items included TypeScript features, API services, config files, JSON schemas, type definition files, environment setup tasks. Murdock processed them all the same way. Features got tests. Config files got tests. Type definitions got tests.
 Murdock’s energy during that first run.
Murdock’s energy during that first run.
Testing a TypeScript interface: does the type compile? Sure, technically you can test that. But why would you? Testing a JSON config file: does it have the right keys? Why would the keys ever change without the code that reads them changing too? Testing an environment setup task: does the env var exist? That’s an integration test for a config file. It tells you nothing useful and breaks the moment someone runs the suite in a different environment.
Thousands of tests later, the suite was a liability. Slow. Brittle. Full of tests that would fail if someone renamed a key in a config file. The CI pipeline crawled. Developers stopped trusting the test output because half the failures were noise.
I ran an audit. 178 test files across six domains. The results:
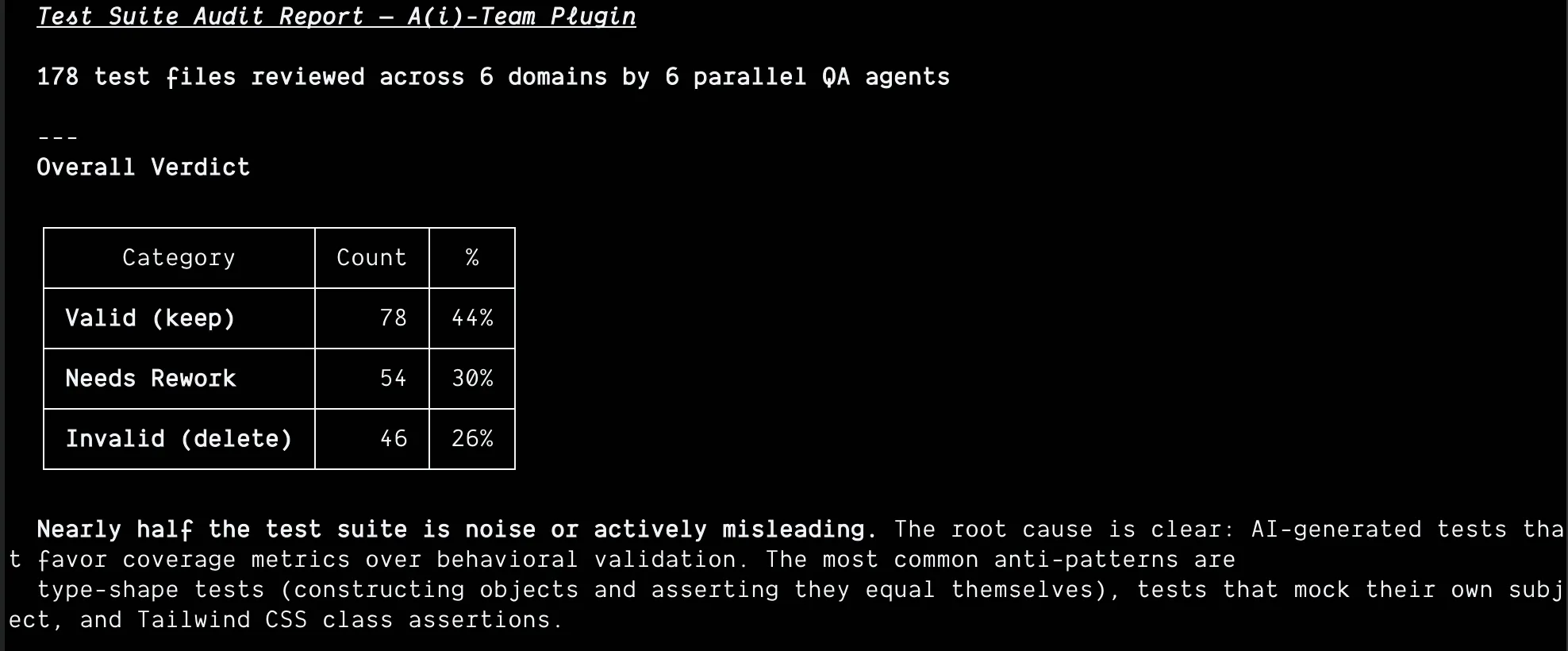 44% valid. 30% needed rework. 26% straight-up deleted.
44% valid. 30% needed rework. 26% straight-up deleted.
Nearly half the test suite was noise or actively misleading. Coverage theater. I told the AI to test everything, and it did - but “testing everything” and “testing everything that matters” are very different things. The result looked thorough. It wasn’t. The most common anti-patterns: type-shape tests that construct objects and assert they equal themselves, tests that mock their own subject, and Tailwind CSS class assertions.
Here’s the deal: the AI wasn’t wrong. I made an assumption. When I said “write tests,” I assumed it would test the things that should be tested. A human developer would make that judgment call. The AI took the instruction literally. I had to rethink my approach and get specific - show it examples of good tests and bad tests, define what’s worth testing and what isn’t.
The Fix
The cleanup alone tells the story: 36 test files deleted, 47 rewritten, 19,300 lines of bad test code removed. 178 test files became 139.
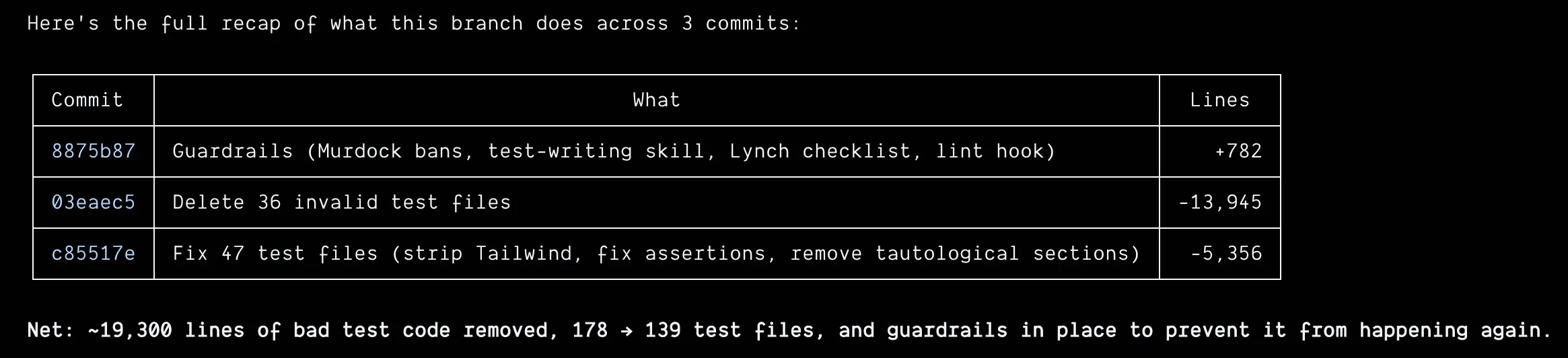 Three commits. 19K lines gone. The test suite lost weight and got smarter.
Three commits. 19K lines gone. The test suite lost weight and got smarter.
But deleting tests isn’t a fix. The fix was making sure the pipeline wouldn’t generate them again. That took a series of adjustments across the whole system.
Work Item Types
First thing I added: types. Not every piece of work is a feature.
- feature - actual behavior that needs real tests. Happy path, error path, edge cases. Three to five tests.
- task - scaffolding work. Config, types, setup. One or two smoke tests max. Does it compile? Does it load? Move on.
- bug - reproduce it, fix it, regression guard. Two to three tests.
- enhancement - new or changed behavior only. Don’t retest what’s already tested.
This single change cut the noise dramatically. Murdock now knows that a config file task needs one test that the config loads. Not fifteen tests checking every key.
Murdock’s New Instructions
I added explicit guidance: test behavior, not implementation. Don’t test that a JSON file has a specific structure. Test that the code using that JSON does what it’s supposed to do.
Don’t chase coverage for its own sake. A codebase with 95% coverage and garbage tests is worse than one with 60% coverage and tests that actually catch regressions.
Three to five tests for a feature is usually enough. If you’re writing twenty, you’re probably testing the wrong things.
Lynch Got a New Job
Lynch is the code reviewer agent. He used to review implementation only. Now he reviews the tests too.
Key question Lynch asks: are these tests testing behavior or implementation details? If Murdock went too far, Lynch sends it back. If the tests are brittle, if they’ll break when you refactor internals, if they’re testing config structure instead of runtime behavior - rejected.
This was the missing feedback loop. Murdock wrote the tests, B.A. (the builder agent) made them pass, but nobody was checking whether the tests were worth passing. Lynch closes that loop.
Hannibal Sets the Frame
Hannibal is the orchestrator. He dispatches work items to the rest of the team. Now he classifies those items before dispatching them.
A config setup task gets different instructions than a feature task. The type travels with the item through every stage. Murdock gets context about what kind of thing he’s testing before he writes a single test.
Getting this right at the orchestration level means Murdock doesn’t have to guess. He knows a task is scaffolding work because Hannibal told him so. The whole pipeline responds to that classification.
The result:
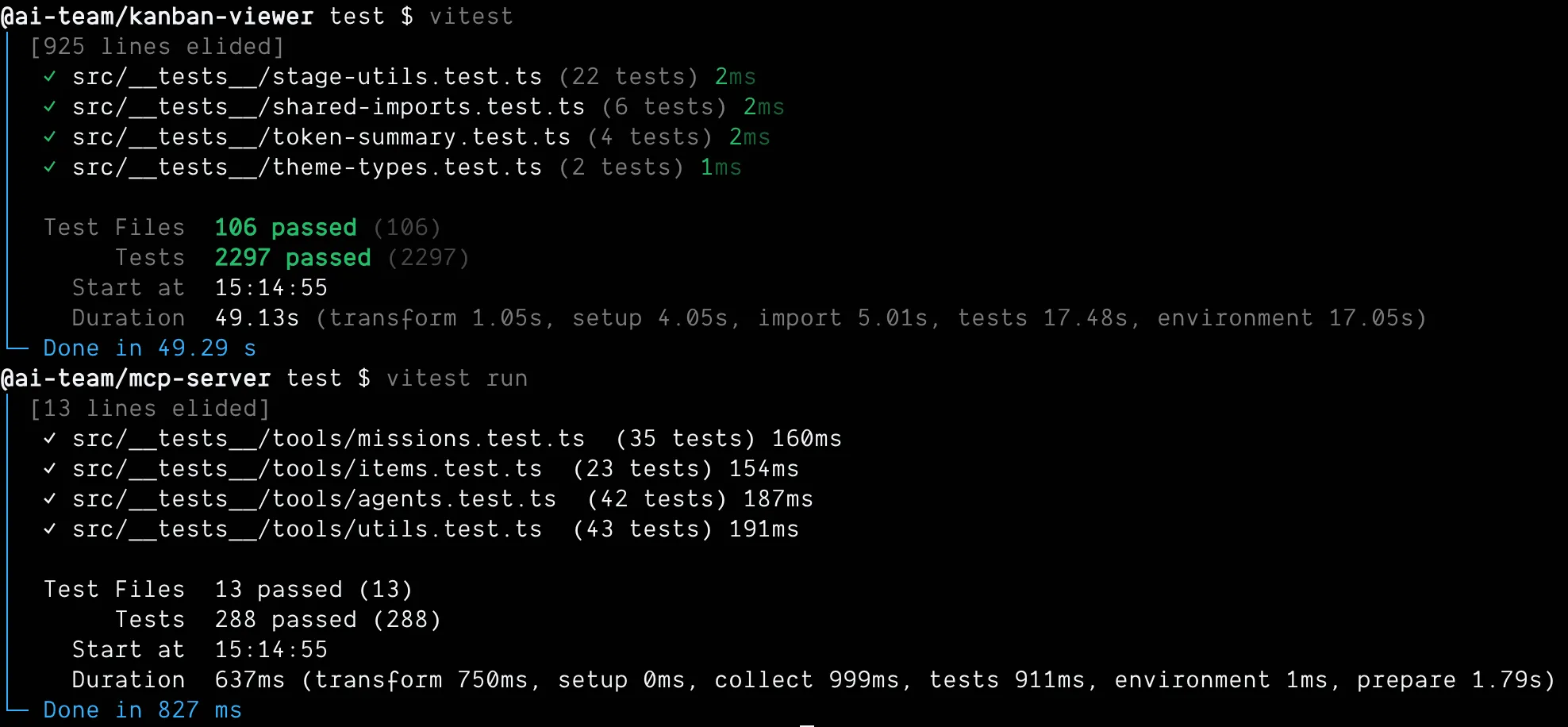 3,397 tests in 117 seconds became 2,525 tests in 50 seconds. All green. Zero failures.
3,397 tests in 117 seconds became 2,525 tests in 50 seconds. All green. Zero failures.
872 fewer tests. More than twice as fast. And every test that’s left is testing something that matters.
The Pipeline Now
Here’s the full team, in order:
Face breaks the PRD into typed, scoped work items. Features, tasks, bugs. Each one classified before anything else happens.
Sosa reviews Face’s breakdown before any code exists. Pokes holes in the scoping. Catches work items that are too big, too vague, or misclassified.
Murdock writes tests appropriate to the work item type. A feature gets three to five behavioral tests. A task gets one smoke test. He writes them before B.A. touches anything.
B.A. implements to pass Murdock’s tests. That’s the whole job. Pass the tests, move on.
Lynch reviews tests AND implementation together. Did B.A. actually solve the problem, or just pass the tests? Are the tests testing the right things? If not, it goes back.
Amy runs after Lynch approves. She hunts for bugs Lynch didn’t catch: edge cases, race conditions, security gaps. Every single feature, no exceptions.
Tawnia handles documentation and the final commit. The mission isn’t done until she commits.
The core principle: the agent that writes the code is never the last agent to look at it.
The kanban board shows all of this in real time. Work items moving through stages, agent names on cards, summaries of what each agent did. When Lynch rejects something, you see it move back. When Amy finds a bug after review, you see it. The whole process is visible.
I’m working on a full writeup on the A(i)-Team - how the flow works, why we built it this way, and what we learned running it on real projects. Stay tuned for that one.
What 3,400 Tests Taught Me
The thing about building with AI agents is that your process becomes visible in a way it never was before.
When a human developer makes a bad call, it’s one bad call. When you encode a bad call into an agent’s instructions, it gets executed perfectly. At scale. Every time. My “test everything” instruction wasn’t a suggestion the AI could push back on. It was a mandate that got applied uniformly across every work item in the pipeline.
3,400 tests wasn’t a bug. It was a mirror. The system showed me exactly where my thinking was sloppy.
The fix required understanding what a test is actually for. Not coverage. Not compliance. Not proving you wrote tests. A test is proof that behavior works. That’s it. If it’s not testing behavior, it’s not adding value; it’s adding noise.
Spoiler alert: I probably still have sloppy thinking in the system. The difference is now I have a pipeline that makes it visible fast. When Murdock writes too many tests, Lynch catches it. When a work item is misclassified, Sosa flags it. The system has feedback loops at every stage.
That’s the real lesson. Building AI agent pipelines forces you to externalize your process. Your assumptions get encoded as instructions. Your blind spots get amplified across hundreds of work items. A human team might quietly work around your bad calls. AI won’t. It just executes.
You build the system. The system reflects your thinking. Fix the thinking, fix the output.
If you want to try the pipeline yourself, The A(i)-Team is on GitHub. If you want help setting this up for your team, check out theaiteam.dev.
Footnotes
-
CodeRabbit - State of AI vs Human Code Generation - AI-generated code has 1.7x more issues, 75% more logic errors, 64% more maintainability issues, 57% more security vulnerabilities. ↩ ↩2